Survivor Bias & The Importance of Proactive Synthetic Testing
In nearly every conversation about Scoutbees, there is one question that customers ask:
“I already have a real-time monitoring solution. ControlUp’s Real-Time Console is already doing an amazing job of showing me everything that happens in my EUC environment; why would I need another monitoring solution?”
The answer is simple: no monitoring strategy can be complete without proactive synthetic testing. Period.
Let’s start with a story.
During World War II, the Allied forces wanted to find a way to minimize the loss of bombers to enemy fire. On the bombers that returned to base safely, the researchers checked the places that were hit the most and concluded that these were the areas that needed to be further fortified. This is a visualization of their results:
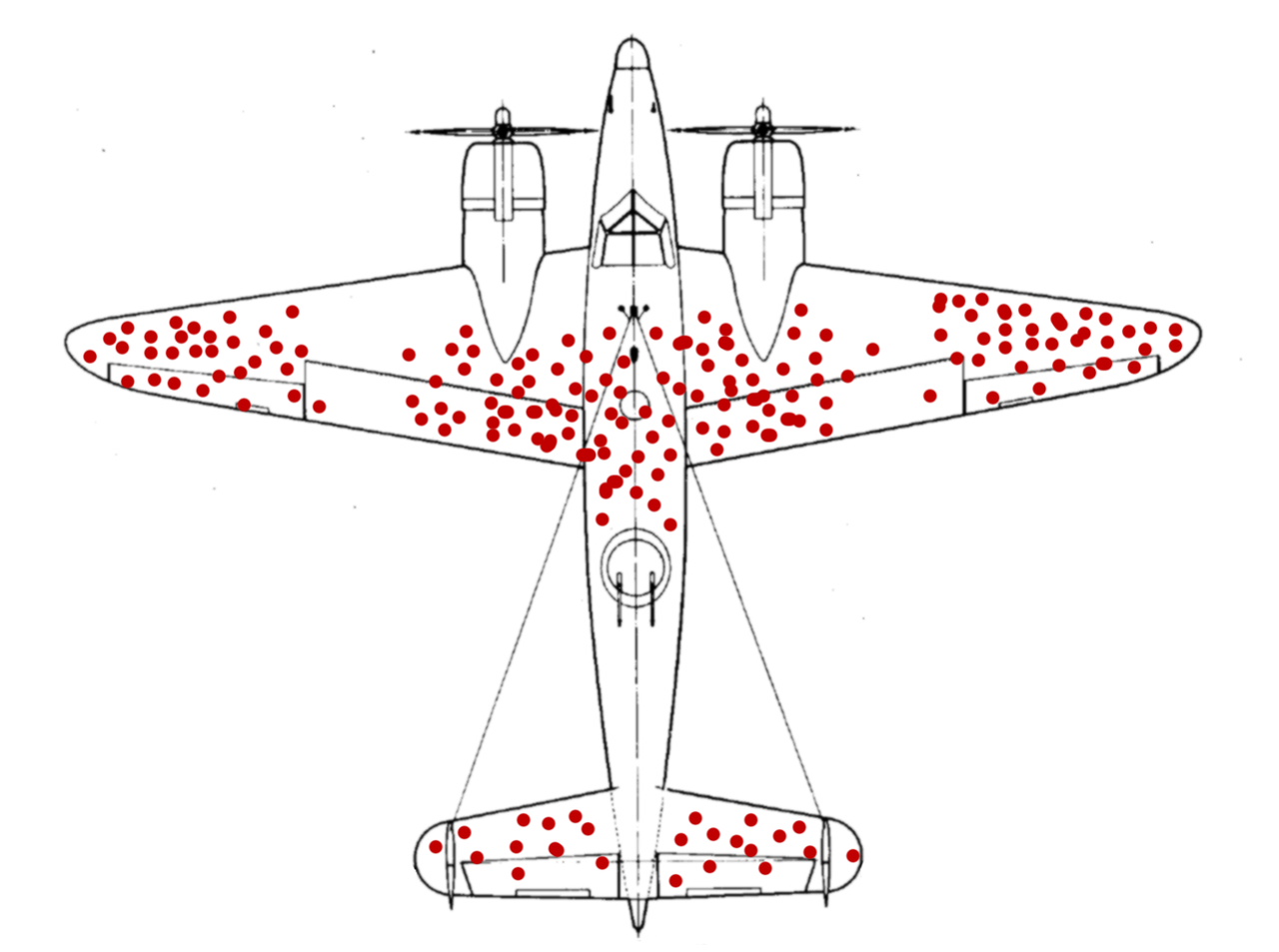
McGeddon, CC BY-SA 4.0, via Wikimedia Commons
But there was a flaw in their vision. A statistician, Abraham Wald, noticed something amiss in the researchers’ approach. They had made their calculations only on the bombers that safely returned to the base; they had completely—not intentionally, of course—forgotten about the bombers that were lost.
So, he took that bias into account and suggested that the areas that would need reinforcing were, in fact, not those that were hit, but the other way around. He recommended strengthening the areas that showed the least damage. His argument was that they could only see the surviving bombers, so they could safely deduce that damage observed on the returning aircrafts was not critical. As such, the areas that need reinforcing were the ones that were not damaged.
This is survivorship bias, in a nutshell.
When we are exposed to the result of a selection process, we can only see the events that have passed through all the hoops and filters. Some typical examples, including those I cited in the story above, are:
- We didn’t have as many ugly buildings in the past as we do today; look how much more tasteful architecture was a century ago. This is because all the ugly buildings have already been demolished.
- Music was so much better in the ‘90s; look at how many bangers there were. People have forgotten the junk music from the 90s because no one ever plays it.
- We don’t have any users facing login issues. Look, our real-time dashboards show all is great. It’s all fine, but let’s give it another hour.
Back in the IT world, we see similar Survivorship Bias instances at play today. But rather than bombers returning to base, we have end users trying to work on their workspaces and apps. We often assume—especially in the era of >99.9% IT availability—that users can log in without issue and that the various components responsible for making the login process smooth are in good shape. Besides… if users were to experience difficulties, they would report this to the help desk right away.
But we know that this is not always the case. People don’t want to fuss with calling Support and think, “If I can’t log in, I’ll just give it a few more minutes and try again.” But what if the issue started to happen at 1:00 a.m. and no one reported it until 8:00 a.m.?
Now, how can we see that our users are really able to log into their apps and desktops when they need to? We need to have a user make a login attempt and then to report on the success status and other details. We also need to have this happen at regular intervals and report all findings in an easily digestible format.
Based on the above, let’s set up some sort of mechanism as follows: we have some sort of test that automatically attempts to log into a virtual workspace or application every five minutes and then generate a visual report with the outcomes and details of each attempt.
And that, in a nutshell, is Proactive Synthetic Testing. To break it down:
- Proactive: carrying out work regularly and consistently rather than waiting for events (such as prolonged downtime) to occur
- Synthetic: having runners carry out automated tests, based on end-user emulations
- Testing: verifying the performance and reliability of our published resources
This is exactly why we created Scoutbees: to alert you about any issues and their root cause(s)—before your users are even aware there’s a problem—so they can stay productive.
Rather than waiting for your end users to experience problems and rely on them to raise a ticket to inform you of what’s happening, Scoutbees can automate the whole process. If you rely on the selection process of users experiencing issues until one of them raises a ticket, you risk all the other unreported instances to be washed by the tide of time.
Scoutbees tests the availability and the responsiveness of your published resources at regular time intervals, reports on all the outcomes and notifies you whenever something goes offline, or just behaves poorly. Not only that, you get a detailed report of exactly where the issue lies so you can easily troubleshoot the problem.

Perhaps something like Scoutbees would have been useful in helping Abraham Wald to prove his point more easily. But when it comes to ‘90s music? I’d rather have Spotify stick with a Best of playlist.
Try Scoutbees for free by signing up for a free trial.